Eliza knows a little something about monkeys. This will become relevant in a moment.
In about 2016, Almeling et al. published a paper that suggested aged Barbary macaques maintained interest in members of their own species while losing interest in novel non-social stimuli (eg toys or puzzles with food inside).
I’d never come across the concept of a Graphical Abstract before, but here is the one for this paper. Graphic design is my passion. Source
This is where Eliza—who knows a little something about monkeys—comes into frame: this did not gel with her experiences at all.
So Eliza (and Mark12, who also knows a little something about monkeys) decided to look into it.
What are the stake?s (According to the papers, not according to me, who knows exactly nothing3 about this type of work)
A big motivation for studying macaques and other non-human primates is that they’re good models of humans. This means that if there was solid evidence of macaques becoming less interested in novel stimuli as they age (while maintaining interest in people), this could suggest an evolutionary reason from this (commonly observed) behaviour in humans.
So if this result is true, it could help us understand the psychology of humans as they age (and in particular, the learned vs evolved trade off they are making).
So what did Eliza and Mark do?
There are a few things you can do when confronted with a result that contradicts your experience: you can complain about it on the Internet, you can mobilize a direct replication effort, or you can conduct your own experiments. Eliza and Mark opted for the third option, designing a conceptual replication.
Direct replications tell you more about the specific experiment that was conducted, but not necessarily more about the phenomenon under investigation. In a study involving aged monkeys4, it’s difficult to imagine how a direct replication could take place.
On the other hand, a conceptual replication has a lot more flexibility. It allows you to probe the question in a more targeted manner, appropriate for incremental science. In this case, Eliza and Mark opted to study only the claim that the monkeys lose interest in novel stimuli as they age (paper here). They did not look into the social claim. They also used a slightly different species of macaque (M. mulatta rather than M. butterfly). This is reasonable insofar as understanding macaques as a model for human behaviour.
What does the data look like?
The experiment used 2435 monkeys aged between 4 and 30 and gave them a novel puzzle task (opening a fancy tube with food in it) for twenty minutes over two days. The puzzle was fitted with an activity tracker. Each monkey had two tries at the puzzle over two days. Monkeys had access to the puzzle for around6 20 minutes.
In order to match the original study’s analysis, Eliza and Mark divided the first two minutes into 15 second intervals and counted the number of intervals where the monkey interacted with the puzzle. They also measured the same thing over 20 minutes in order to see if there was a difference between short-term curiosity and more sustained exploration.
For each monkey, we have the following information:
Monkey ID
Age (4-30)
Day (one or two)
Number of active intervals in the first two minutes (0-8)
Number of active intervals in the first twenty minutes (0-80)
The data and their analysis are freely7 available here.
library(tidyverse)acti_data <-read_csv("activity_data.csv") activity_2mins <- acti_data |>filter(obs<9) |>group_by(subj_id, Day) |>summarize(total=sum(Activity), active_bins =sum(Activity >0), age =min(age)) |>rename(monkey = subj_id, day = Day) |>ungroup()activity_20minms80 <- acti_data |>filter(obs<81) |>group_by(subj_id, Day) |>summarize(total=sum(Activity), active_bins =sum(Activity >0), age =min(age)) |>rename(monkey = subj_id, day = Day) |>ungroup()glimpse(activity_20minms80)
Eliza and Mark’s monkey data is an example of a fairly common type of experimental data, where the same subject is measured multiple times. It is useful to break the covariates down into three types: grouping variables, group-level covariates, and individual-level covariates.
Grouping variables indicate what group each observation is in. We will see a lot of different ways of defining groups as we go on, but a core idea is that observations within a group should conceptually more similar to each other than observations in different groups. For Eliza and Mark, their grouping variable is monkey. This encodes the idea that different monkeys might have very different levels of curiosity, but the same monkey across two different days would probably have fairly similar levels of curiosity.
Group-level covariates are covariates that describe a feature of the group rather than the observation. In this example, age is a group-level covariate, because the monkeys are the same age at each observation.
Individual-level covariates are covariates that describe a feature that is specific to an observation. (The nomenclature here can be a bit confusing: the “individual” refers to individual observations, not to individual monkeys. All good naming conventions go to shit eventually.) The individual-level covariate is experiment day. This can be a bit harder to see than the other designations, but it’s a little clearer if you think of it as an indicator of whether this is the first time the monkey has seen the task or the second time. Viewed this way, it is very clearly a measurement of an property of an observation rather than of a group.
Eliza and Mark’s monkey data is an example of a fairly general type of experimental data where subjects (our groups) are given the same task under different experimental conditions (described through individual-level covariates). As we will see, it’s not uncommon to have much more complex group definitions (that involve several grouping covariates) and larger sets of both group-level and individual-level covariates.
So how do we fit a model to this data.
There are just too many monkeys; or Why can’t we just analyse this with regression?
The temptation with this sort of data is to fit a linear regression to it as a first model. In this case, we are using grouping, group-level, and individual-level covariates in the same way. Let’s suck it and see.
library(broom)fit_lm <-lm(active_bins ~ age*factor(day) +factor(monkey), data = activity_2mins)tidy(fit_lm)
So the first thing you will notice is that that is a lot of regression coefficients! There are 243 monkeys and 2 days, but only 485 observations. This isn’t enough data to reliably estimate all of these parameters. (Look at the standard errors for the monkey-related coefficients. They are huge!)
So what are we to do?
The problem is the monkeys. If we use monkey as a factor variable, we only have (at most) two observations of each factor level. This is simply not enough observations per to estimate a different intercept for each monkey!
This type of model is often described as having no pooling, which indicates that there is no explicit dependence between the intercepts for each group (monkey). (There is some dependence between groups due to the group-level covariate age.)
If we ignore the monkeys, will they go away? or Another attempt at regression
Our first attempt at a regression model didn’t work particularly well, but that doesn’t mean we should give up8. A second option is that we can assume that there is, fundamentally, no difference between monkeys. If all monkeys of the same age have similar amounts of interest in new puzzles, this would be a reasonable assumption. The best case scenario is that not accounting for differences between individual monkeys would still lead to approximately normal residuals, albeit with probably a larger residual variance.
This type of modelling assumption is called complete pooling as it pools the information between groups by treating them all as the same.
Let’s see what happens in this case!
fit_lm_pool <-lm(active_bins ~ age*factor(day), data = activity_2mins)summary(fit_lm_pool)
Call:
lm(formula = active_bins ~ age * factor(day), data = activity_2mins)
Residuals:
Min 1Q Median 3Q Max
-4.5249 -1.5532 0.1415 1.6731 4.1884
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.789718 0.344466 11.002 <2e-16 ***
age 0.003126 0.021696 0.144 0.885
factor(day)2 0.056112 0.488818 0.115 0.909
age:factor(day)2 0.025170 0.030759 0.818 0.414
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.103 on 481 degrees of freedom
Multiple R-squared: 0.01365, Adjusted R-squared: 0.0075
F-statistic: 2.219 on 3 and 481 DF, p-value: 0.0851
On the up side, the regression runs and doesn’t have too many parameters!
The brave and the bold might even try to interpret the coefficients and say something like there doesn’t seem to be a strong effect of age. But there’s real danger in trying to interpret regression coefficients in the presence of a potential confounder (in this case, the monkey ID). And it’s particularly bad form to do this without ever looking at any sort of regression diagnostics. Linear regression is not a magic eight ball.
Let’s look at the diagnostic plots.
library(broom)augment(fit_lm_pool) |>ggplot(aes(x = .fitted, y = active_bins - .fitted)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +theme_classic()
There are certainly some patterns in those residuals (and some suggestion that the error need a heavier tail for this model to make sense).
What is between no pooling and complete pooling? Multilevel models, that’s what
We are in a Goldilocks situation: no pooling results in a model that has too many independent parameters for the amount of data that we’ve got, while complete pooling has too few parameters to correctly account for the differences between the monkeys. So what is our perfectly tempered porridge9?
The answer is to assume that each monkey has its own intercept, but that it’s intercept can only be so far from the overall intercept (that we would’ve gotten from complete pooling). There are a bunch of ways to realize this concept, but the classical method is to use a normal distribution.
In particular, if the \(j\)th monkey has observations \(y_{ij}\), \(i=1,2\), then we can write our model as \[
y_{ij} \sim N(\mu_j + \beta_\text{age}\, \text{age}_j + \beta_\text{day}\, \text{day}_{ij} + \beta_\text{age,day}\, \text{[age*day]}_{ij}, \sigma^2).
\]
The effects of age and day and the data standard deviation (\(\sigma\)) are just like they’d be in an ordinary linear regression model. Our modification comes in how we treat the \(\mu_j\).
In a classical linear regression model, we would fit the \(\mu_j\)s independently, perhaps with some weakly informative prior distribution. But we’ve already discussed that that won’t work.
Instead we will make the \(\mu_j\)exchangeable rather than independent. Exchangeability is a relaxation of the independence assumption to say instead encode that we have no idea which of the intercepts will do what. That is, if we switch around the labels of our intercepts the prior should not change. There is a long and storied history of exchangeable models in statistics, but the short version that is more than sufficient for our purposes is that they usually10 take the form \[\begin{align*}
\mu_j \mid \tau \stackrel{\text{iid}}{\sim} &p(\mu_j \mid \tau), \qquad i = 1,\ldots, J \\
\tau \sim & p(\tau).
\end{align*}\]
In a regression context, we typically assume that \[
\mu_j \mid \tau \sim N(\mu, \tau^2)
\] for some \(\mu\) and \(\tau\) that will need their own priors.
We can explore this difference mathematically. The regression model, which assumes independence of the \(\mu_j\), uses \[
p(\mu_1, \ldots, \mu_J) = \prod_{j=1}^J N(\mu, \tau_\text{fixed}^2)
\] as the joint prior on \(\mu_1,\ldots,\mu_J\). On the other hand, the exchangeable model, which forms the basis of multilevel models, assumes the joint prior \[
p(\mu_1, \ldots, \mu_J) = \int_0^\infty \left(\prod_{j=1}^J N(\mu, \tau^2)\right)p(\tau)\,d\tau,
\] for some prior on \(p(\tau)\) on \(\tau\).
This might not seem like much of a change, but it can be quite profound. In both cases, the prior is saying that each \(\mu_j\) is, with high probability, at most \(3\tau\) away from the overall mean \(\mu\). The difference is that while the classical least squares formulation uses a fixed value of \(\tau\) that needs to be specified by the modeller, while the exchangeable model lets \(\tau\) adapt to the data.
This data adaptation is really nifty! It means that if the groups have similar means, they can borrow information from the other groups (via the narrowing of \(\tau\)) in order to improve their precision over an unpooled estimate. On the other hand, if there is a meaningful difference between the groups11, this model can still represent that, unlike the unpooled model.
In our context, however, we need a tiny bit more. We have a group-level covariate (specifically age) that we think is going to effect the group mean. So the model we want is \[\begin{align*}
y_{ij} \mid \mu_j,\beta, \sigma &\sim N(\mu_j + \beta_\text{day}\, \text{day}_{ij} + \beta_\text{age,day}\, \text{[age*day]}_{ij} , \sigma^2) \\
\mu_j\mid \tau, \mu,\beta &\sim N(\mu + \beta_\text{age}\, \text{age}_j, \tau^2) \\
\mu &\sim p(\mu)\\
\beta &\sim p(\beta)\\
\tau & \sim p(\tau) \\
\sigma &\sim p(\sigma).
\end{align*}\]
In order to fully specify the model we need to set the four prior distributions.
This is an example of a multilevel12model. The name comes from the data having multiple levels (in this case two: the observation level and the group level). Both levels have an appropriate model for their mean.
This mathematical representation does a good job in separating out the two different levels. However, there are a lot of other ways of writing multilevel models. An important example is the extended formula notation created13 by R’s lme4 package. In their notation, we would write this model as
formula <- active_bins_scaled ~ age_centred*day + (1| monkey)
The first bit of this formula is the same as the formula used in linear regression. The interesting bit is is the (1 | monkey). This is the way to tell R that the intercept (aka 1 in formula notation) is going to be grouped by monkey and we are going to put an exchangeable normal prior on it. For more complex models there are more complex variations on this theme, but for the moment we won’t go any further.
Reasoning out some prior distributions
We need to set priors. The canny amongst you may have noticed that I did not set priors in the previous two examples. There are two reasons for this: firstly I didn’t feel like it, and secondly none but the most terrible prior distributions would have meaningfully changed the conclusions. This is, it turns out, one of the great truths when it comes to prior distributions: they do not matter until they do14.
In particular, if you have a parameter that directly sees the data (eg it’s in the likelihood) and there is nothing weird going on15, then the prior distribution will usually not do much as any prior will be quickly overwhelmed by the data.
The problem is that we have one parameter in our model (\(\tau\)) that does not directly see the data. Instead of directly telling us about an observation, it tells us about how different the groups of observations are. There is usually less information in the data about this type of parameter and, consequently, the prior distribution will be more important. This is especially true when you have more than one grouping variable, or when a variable only has a small number of groups.
So let’s pay some proper attention to the priors.
To begin with, let’s set priors on \(\mu\), \(\beta\), and \(\sigma\) (aka the data-level parameters). This is a considerably easier task if the data is scaled. Otherwise, you need to encode information about the usual scale16 of the data into your priors. Sometimes this is a sensible and easy thing to do, but usually it’s easier to simply scale the data. (A lot of software will simply scale your data for you, but it is always better to do it yourself!)
So let’s scale our data. We have three variables that need scaling: age (aka the covariate that isn’t categorical) and active_bins (aka the response). For age, we are going to want to measure it as either years from the youngest monkey or years from the average monkey. I think, in this situation, the first version could make a lot of sense, but we are going with the second. This allows us to interpret \(\mu\) as the over-all mean. Otherwise, \(\mu\) would tell us about the overall average activity of 4 year old monkeys and we will use \(\beta(\text{age}_j - 4)\) to estimate how much the activity changes, on average keeping all other aspects constant, as the monkey ages.
On the other hand, we have no sensible baseline for activity, so deviation from the average seems like a sensible scaling. I also don’t know, a priori, how variable activity is going to be, so I might want to scale17 it by its standard deviation. In this case, I’m not going to do that because we have a sensible fixed18 upper limit (8), which I can scale by.
One important thing here is that if we scale the data by data-dependent quantities (like the minimum, the mean, or the standard deviation) we must keep track of this information. This is because any future data we try to predict with this model will need to be transformed the same way using the same19numbers! This particularly has implication when you are doing things like test/training set validation or cross validation: in the first case, the test set needs to be scaled in the same way the training set was; while in the second case each cross validation training set needs to be scaled independently and that scaling needs to be used on the corresponding left-out data20.
With our scaling completed, we can now start thinking about prior distributions. The trick with priors is to make them wide enough to cover all plausible values of a parameter without making them so wide that they put a whole bunch of weight on essentially silly values.
We know, for instance, that our unscaled activity will go between 0 and 8. That means that it’s unlikely for the mean of the scaled process to be much bigger than 3 or 4. These considerations, along with the fact that we have centred the data so the mean should be closer to zero, suggest that a \(N(0,1)\) prior should be appropriate for \(\mu\).
As we normalised our age data relative to the smallest age, we should think more carefully about the scaling of \(\beta\). Macaques live for 20-3021 years, so we need to think about, for instance, an ordinary aged macaque that would be 15 years older than the baseline. Thanks to our scaling, the largest change that we can have is around 1, which strongly suggests that if \(\beta\) was too much larger than \(1/8\) we are going to be in unreasonable territory. So let’s put a \(N(0,0.2^2)\) prior22 on \(\beta_\text{age}\) and \(\beta_\text{age,day}\). For \(\beta_\text{day}\) we can use a \(N(0,1)\) prior.
Similarly, the scaling of activity_bins suggests that a \(N(0,1)\) prior would be sufficient for the data-level standard deviation \(\sigma\).
That just leaves us with our choice of prior for the standard deviation of the intercept23\(\mu_j\), \(\tau\). Thankfully, we considered this case in detail in the previous blog post. There I argued that a sensible prior for \(\tau\) would be an exponential prior. To be quite honest with you, a half-normal or a half-t also would be fine. But I’m going to stick to my guns. For the scaling, again, it would be a touch surprising (given the scaling of the data) if the group means were more than 3 apart, so choosing \(\lambda=1\) in the exponential distribution should give a relatively weak prior without being so wide that we are putting prior mass on a bunch of values that we would never actually want to put prior mass on.
We can then fit the model with brms. In this case, I’m using the cmdstanr back end, because it’s fast and I like it.
To specify the model, we use the lme4-style formula notation discussed above.
To set the priors, we will use brms. Now, if you are Paul you might be able to remember how to set priors in brms without having to look it up, but I am sadly not Paul24, so every time I need to set priors in brms I write the formula and use the convenient get_prior function
From this, we can see that the default prior on \(\beta\) is an improper flat prior, the default prior on the intercept is a Student-t with 3 degrees of freedom centred at zero with standard deviation 2.5. The same prior (restricted to positive numbers) is put on all of the standard deviation parameters. These default prior distributions are, to be honest, probably fine in this context25, but it is good practice to always set your prior.
We do this as follows. (Note that brms uses Stan, which parameterises the normal distribution by its mean and standard deviation!)
priors <-prior(normal(0, 0.2), coef ="age_centred") +prior(normal(0,0.2), coef ="age_centred:day2") +prior(normal(0, 1), coef ="day2") +prior(normal(0,1), class ="sigma") +prior(exponential(1), class = sd) +# tauprior(normal(0,1), class ="Intercept")priors
Pre-experiment prophylaxis
So we have specified some priors using the power of our thoughts. But we should probably check to see if they are broadly sensible. A great thing about Bayesian modelling is that we are explicitly specifying our a priori (or pre-data) assumptions about the data generating process. That means that we can do a fast validation of our priors by simulating from them and checking that they’re not too wild.
There are lots of ways to do this, but the easiest26 way to do this is to use the sample_prior = "only" option in the brm() function.
Running MCMC with 4 parallel chains...
Chain 1 finished in 0.7 seconds.
Chain 2 finished in 0.7 seconds.
Chain 3 finished in 0.7 seconds.
Chain 4 finished in 0.7 seconds.
All 4 chains finished successfully.
Mean chain execution time: 0.7 seconds.
Total execution time: 0.9 seconds.
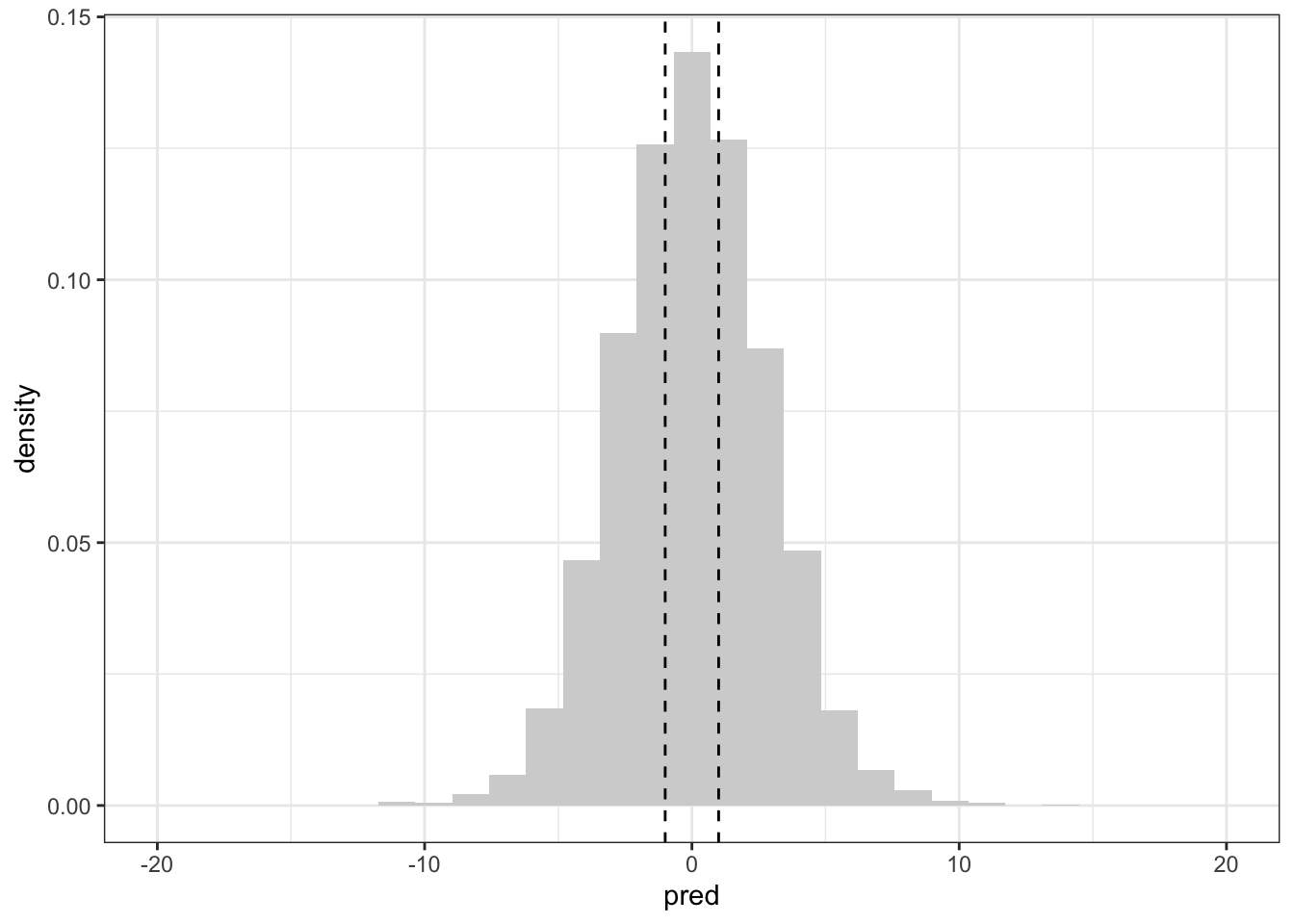
Now that we have samples from the prior distribution, we can assemble them to work out what our prior tells us we would, pre-data, predict for the number of active bins for a single monkey (in this a single monkey27 that is 10 years older than the baseline).
The vertical lines are (approximately) the minimum and maximum of the data. This28 suggests that the implied priors are definitely wider than our observed data, but they are not several orders of magnitude too wide. This is a good situation to be in: it gives enough room in the priors that we might be wrong with our specification while also not allowing for truly wild values of the parameters (and implied predictive distribution). One could even go so far as to say that the prior is weakly informative.
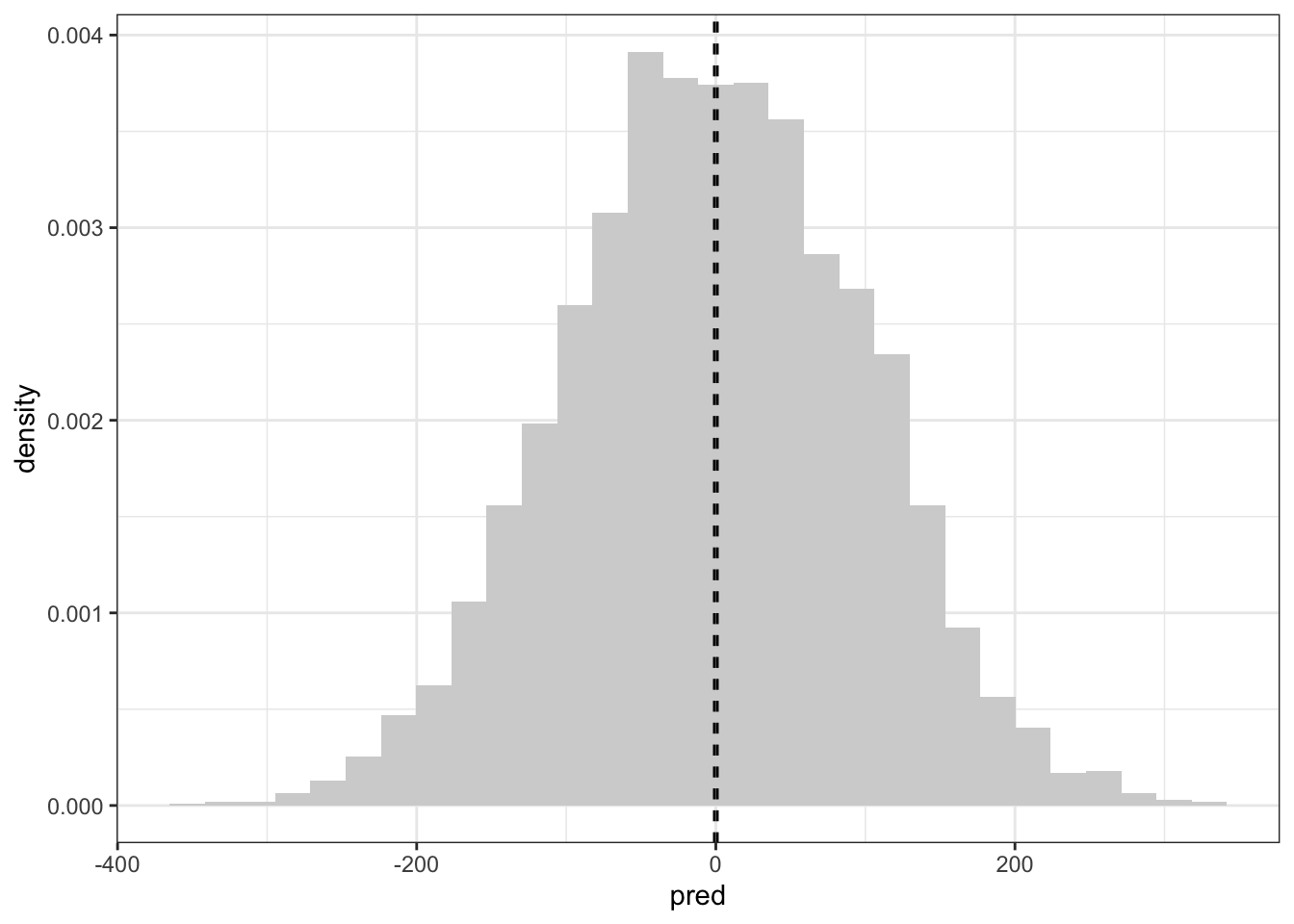
Let’s compare this to the default priors on the standard deviation parameters. (The default priors on the regression parameters are improper so we can’t simulate from them. So I replaced the improper prior with a much narrower \(N(0,10^2)\) prior. If you make the prior on the \(\beta\) wider the prior predictive distribution also gets wider.)
priors_default <-prior(normal(0,10), class ="b")prior_draws_default <-brm(formula, data = activity_2mins_scaled,prior = priors_default,sample_prior ="only",backend ="cmdstanr",cores =4,refresh =0)
Running MCMC with 4 parallel chains...
Chain 1 finished in 0.6 seconds.
Chain 2 finished in 0.6 seconds.
Chain 3 finished in 0.6 seconds.
Chain 4 finished in 0.6 seconds.
All 4 chains finished successfully.
Mean chain execution time: 0.6 seconds.
Total execution time: 0.8 seconds.
Fitting the data; or do my monkeys get less interesting as they age
With all of that in hand, we can now fit the data. Hooray. This is done with the same command (minus the sample_prior bit).
posterior_draws <-brm(formula, data = activity_2mins_scaled,prior = priors,backend ="cmdstanr",cores =4,refresh =0)
Start sampling
Running MCMC with 4 parallel chains...
Chain 1 finished in 1.7 seconds.
Chain 3 finished in 1.8 seconds.
Chain 2 finished in 1.8 seconds.
Chain 4 finished in 1.8 seconds.
All 4 chains finished successfully.
Mean chain execution time: 1.8 seconds.
Total execution time: 2.0 seconds.
posterior_draws
Family: gaussian
Links: mu = identity; sigma = identity
Formula: active_bins_scaled ~ age_centred * day + (1 | monkey)
Data: activity_2mins_scaled (Number of observations: 485)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Group-Level Effects:
~monkey (Number of levels: 243)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.31 0.03 0.25 0.37 1.00 1070 1766
Population-Level Effects:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -0.04 0.03 -0.11 0.02 1.00 4222 3171
age_centred 0.02 0.07 -0.11 0.14 1.00 3671 3150
day2 0.10 0.04 0.03 0.18 1.00 8022 2911
age_centred:day2 0.07 0.07 -0.08 0.22 1.00 6170 2584
Family Specific Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 0.43 0.02 0.39 0.47 1.00 1613 2430
Draws were sampled using sample(hmc). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
There doesn’t seem to be much of an effect of age in this data.
If you’re curious, this matches well29 with the output of lme4, which is a nice sense check for simple models. Generally speaking, if they’re the same then they’re both fine. If they are different30, then you’ve got to look deeper.
Linear mixed model fit by REML ['lmerMod']
Formula: active_bins_scaled ~ age_centred * day + (1 | monkey)
Data: activity_2mins_scaled
REML criterion at convergence: 734.9096
Random effects:
Groups Name Std.Dev.
monkey (Intercept) 0.3091
Residual 0.4253
Number of obs: 485, groups: monkey, 243
Fixed Effects:
(Intercept) age_centred day2 age_centred:day2
-0.04114 0.01016 0.10507 0.08507
We can also compare the fit using leave-one-out cross validation. This is similar to AIC, but more directly interpretable. It is the average of \[
\log p_\text{posterior predictive}(y_{ij} \mid y_{-ij}) = \log \left(\int_\theta p(y_{ij} \mid \theta)p(\theta \mid y_{-ij})\, d\theta\right),
\] where \(\theta\) is a vector of all of the parameters in the model. The notation \(y_{-ij}\) is the data without the \(ij\)th observation. This average is sometimes called the expected log predictive density or elpd.
To compare it with the two linear regression models, I need to fit them in brms. I will use a \(N(0,1)\) prior for the monkey intercepts and the same priors as the previous model for the other parameters.
priors_lm <-prior(normal(0,1), class ="b") +prior(normal(0, 0.2), coef ="age_centred") +prior(normal(0,0.2), coef ="age_centred:day2") +prior(normal(0, 1), coef ="day2") +prior(normal(0,1), class ="Intercept") +prior(normal(0,1), class ="sigma")posterior_nopool <-brm( active_bins_scaled ~ age_centred * day + monkey, data = activity_2mins_scaled,prior = priors_lm,backend ="cmdstanr",cores =4,refresh =0)
Running MCMC with 4 parallel chains...
Chain 1 finished in 4.5 seconds.
Chain 3 finished in 4.5 seconds.
Chain 2 finished in 4.5 seconds.
Chain 4 finished in 4.5 seconds.
All 4 chains finished successfully.
Mean chain execution time: 4.5 seconds.
Total execution time: 4.7 seconds.
Running MCMC with 4 parallel chains...
Chain 1 finished in 0.1 seconds.
Chain 2 finished in 0.1 seconds.
Chain 3 finished in 0.1 seconds.
Chain 4 finished in 0.1 seconds.
All 4 chains finished successfully.
Mean chain execution time: 0.1 seconds.
Total execution time: 0.3 seconds.
We an now use the loo_compare function to compare the models. By default, the best model is listed first and the other models are listed below it with the difference in elpd values given. To do this, we need to tell brms to compute the loo criterion using the add_criterion function.
Warning: Found 2 observations with a pareto_k > 0.7 in model 'posterior_draws'.
It is recommended to set 'moment_match = TRUE' in order to perform moment
matching for problematic observations.
Warning: Found 63 observations with a pareto_k > 0.7 in model
'posterior_nopool'. It is recommended to set 'moment_match = TRUE' in order to
perform moment matching for problematic observations.
There are some warnings there suggesting that we could recompute these using a slower method, but for the purposes of today I’m not going to do that and I shall declare that the multilevel model performs far better than the other two models.
Post-experiment prophylaxis
Of course, we would be fools to just assume that because we fit a model and compared it to some other models, the model is a good representation of the data. To do that, we need to look at some posterior checks.
The easiest thing to look at is the predictions themselves.
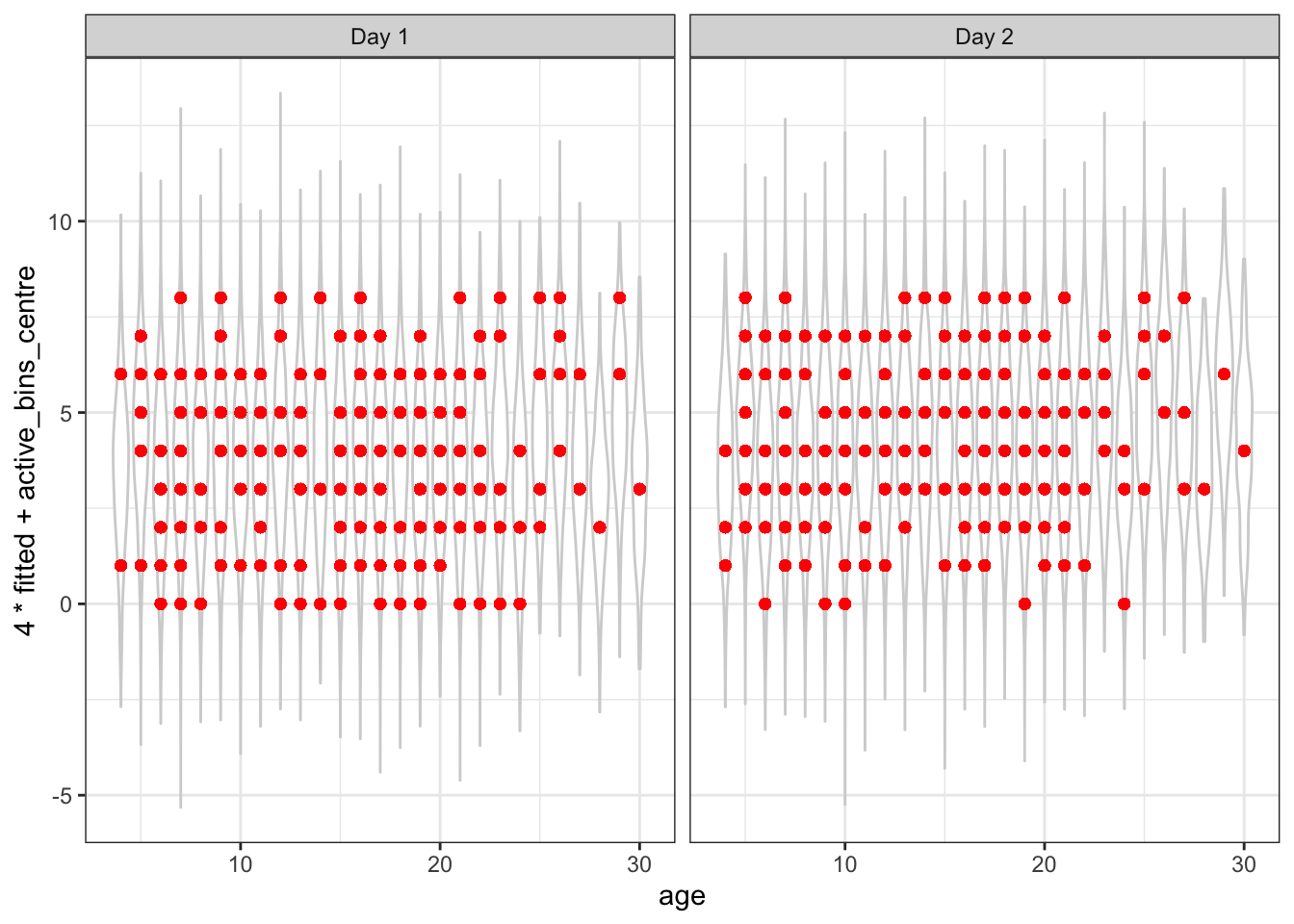
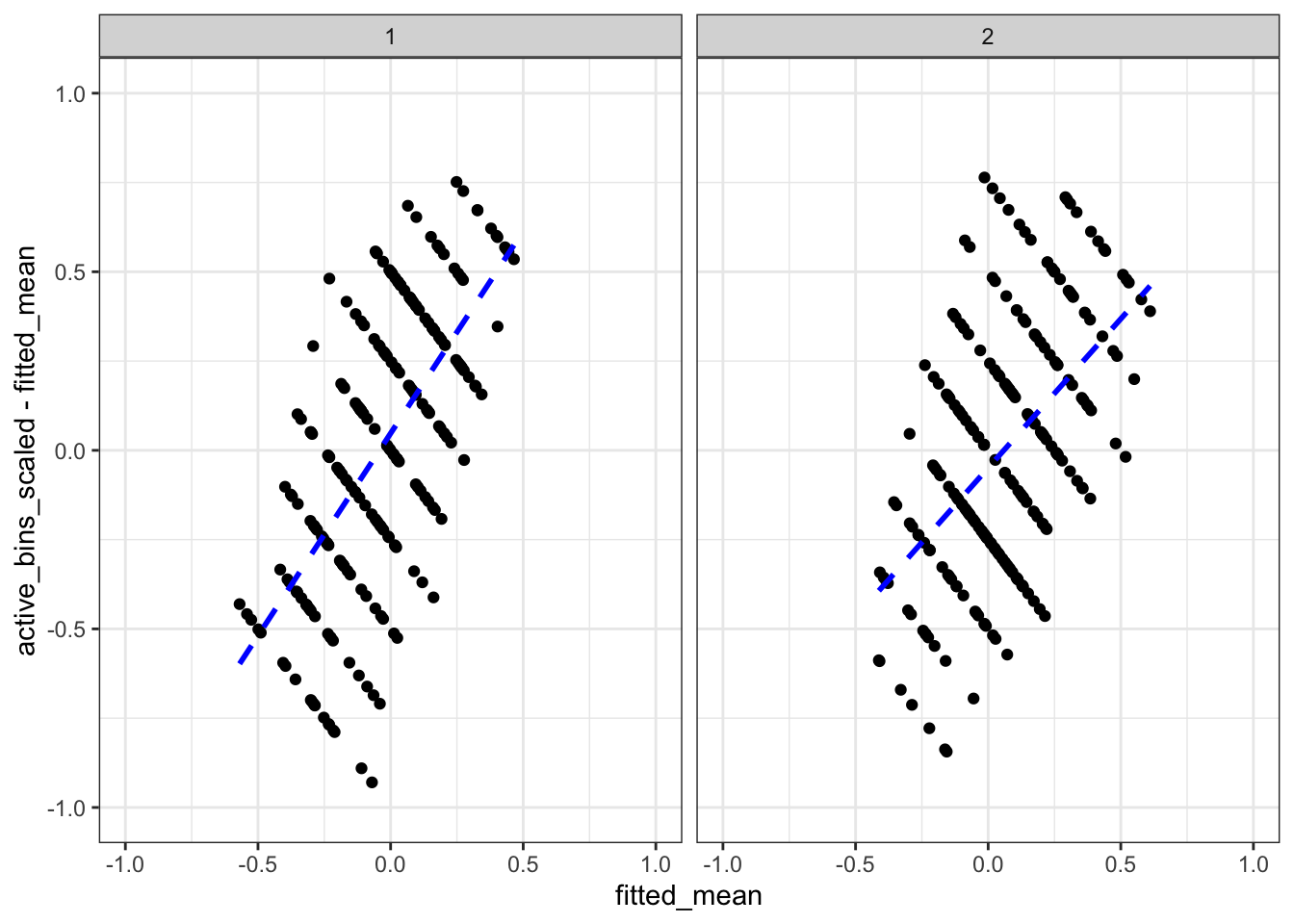
That appears to be a reasonably good fit, although it’s possible that the prediction intervals are a bit wide. We can also look at the plot of the posterior residuals vs the fitted values. Here the fitted values are the mean of the posterior predictive distribution.
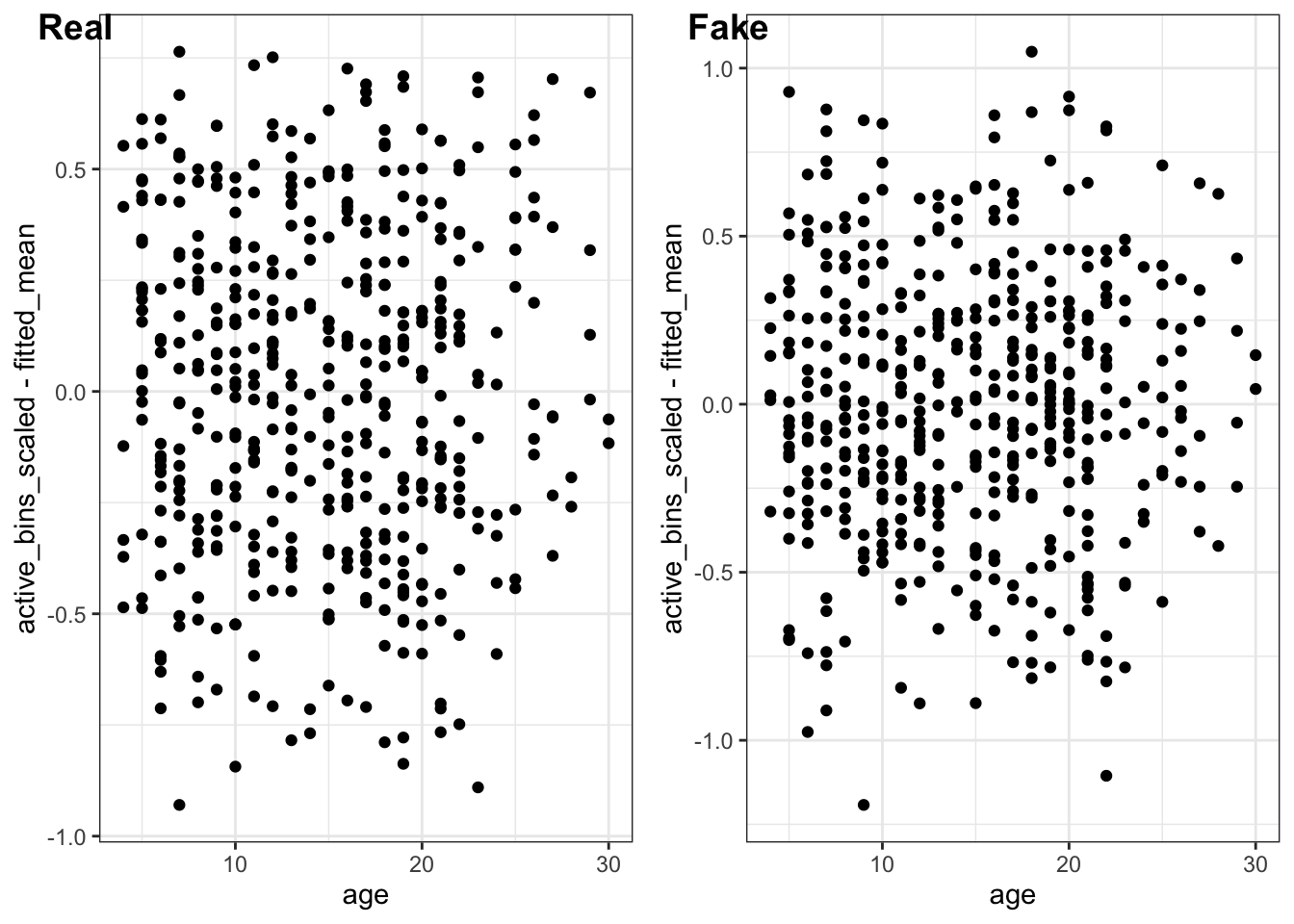
Next, let’s check for evidence of non-linearity in age.
There doesn’t seem to be any obvious evidence of non-linearity in the residuals, which suggests the linear model for age was sufficient.
We can also check the distributional assumption31 that the residuals \[
r_{ij} = y_{ij} - \mu_j
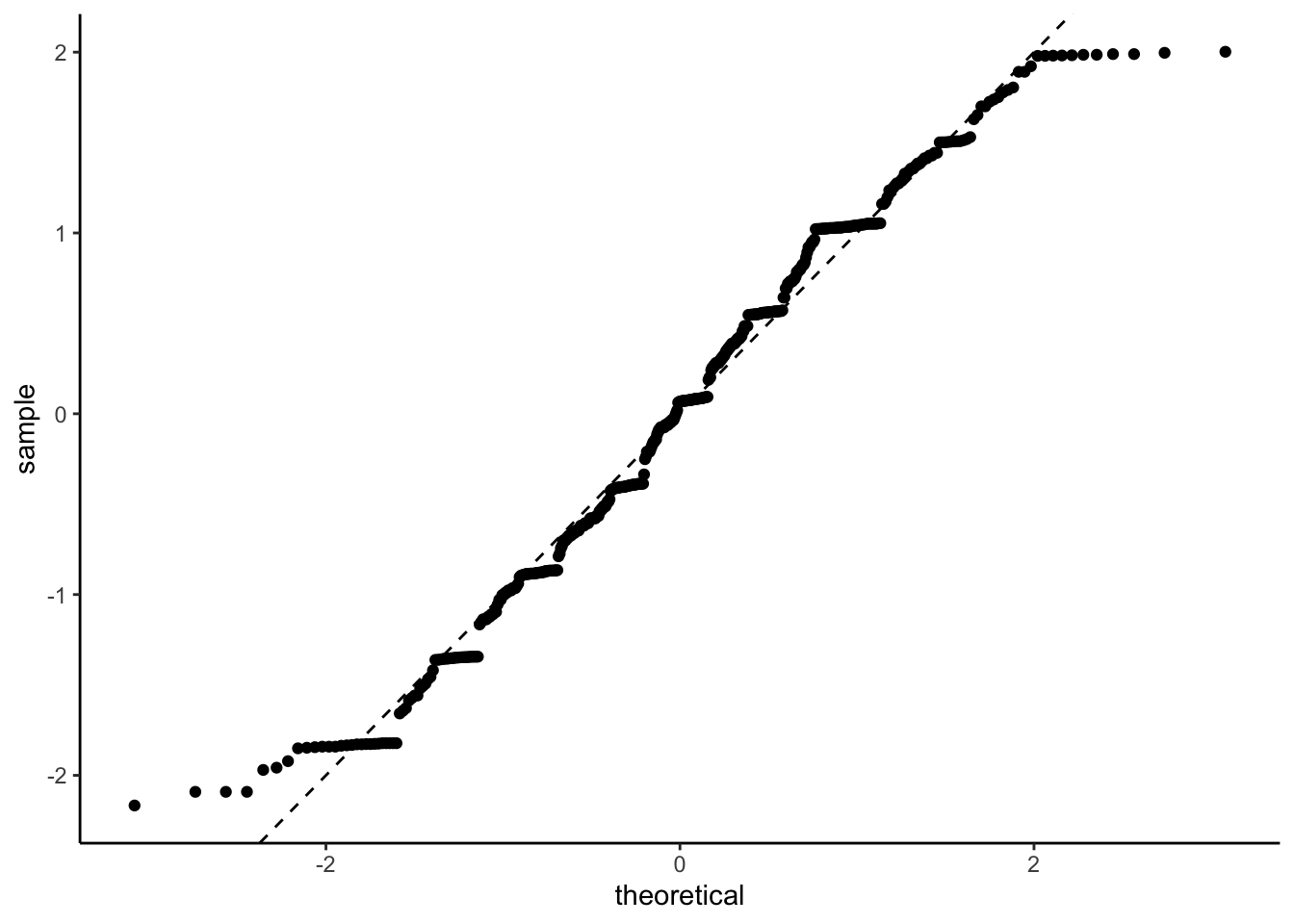
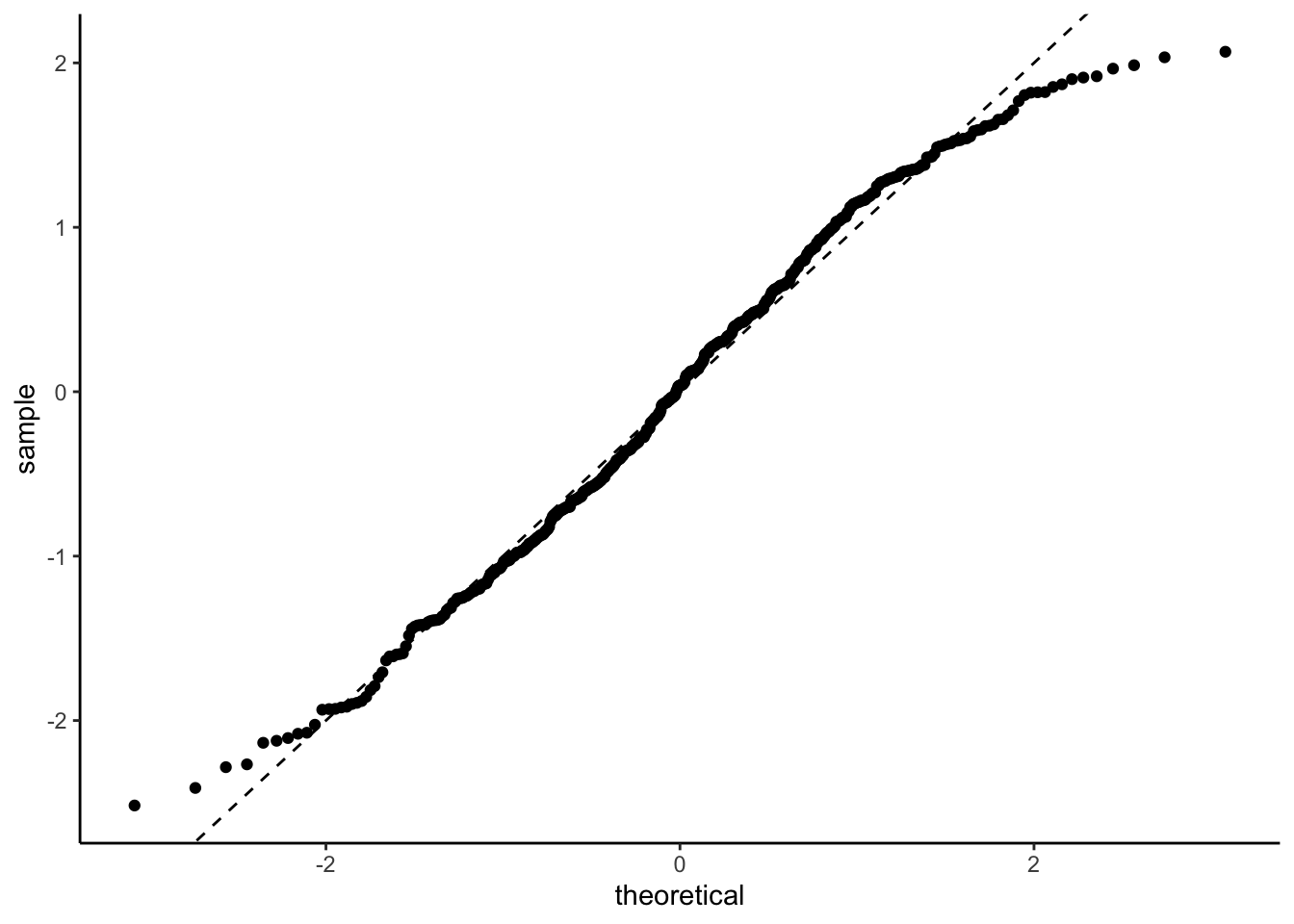
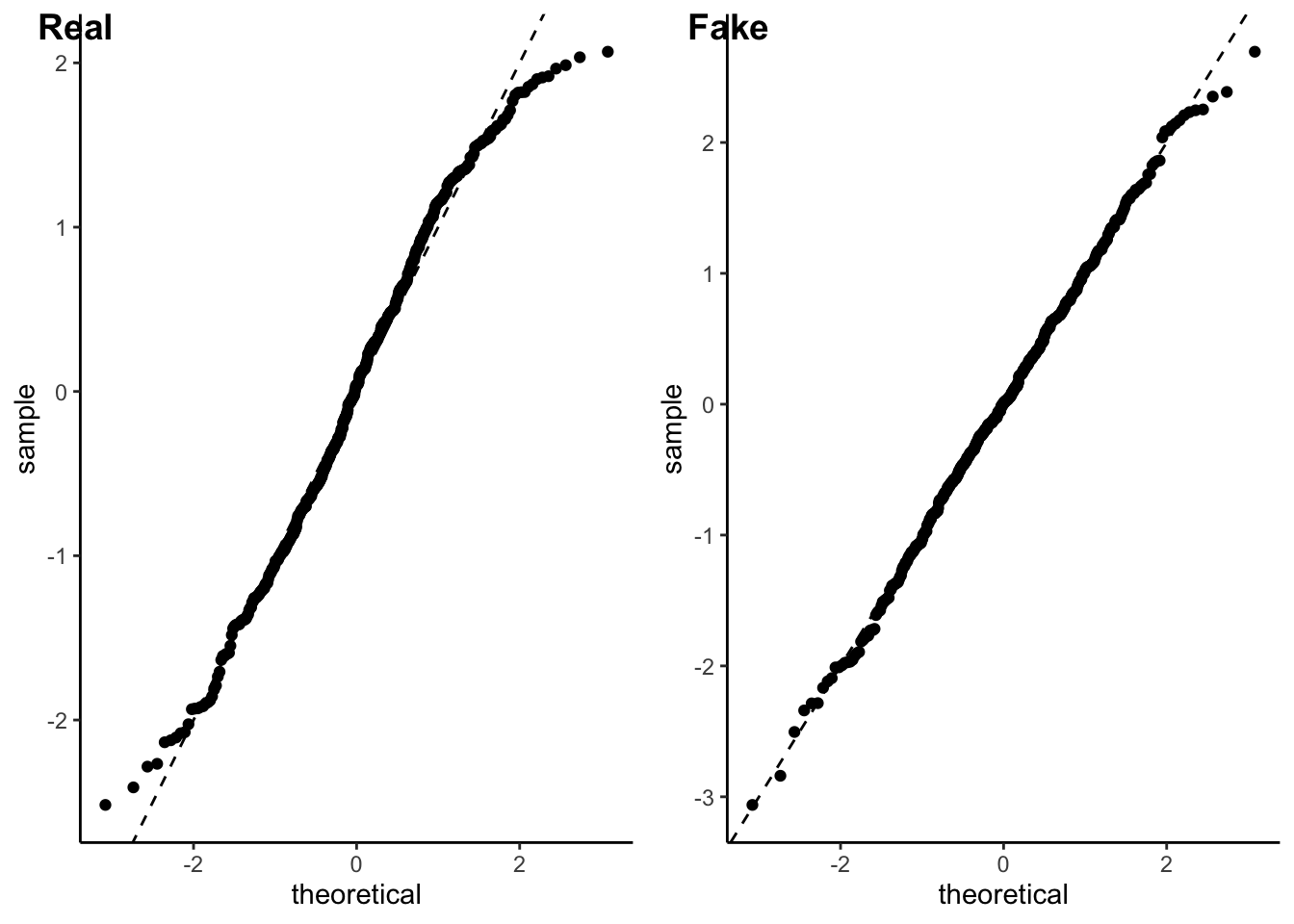
\] have a Gaussian distribution. We can check this with a qq-plot. Here we are using the posterior mean to define our residuals.
We can look at the qq-plot to see how we’re doing with normality.
That’s not too bad. A bit of a deviation from normality in the tails but nothing that would make me weep. It could well be an artifact of how I defined and normalised the residuals.
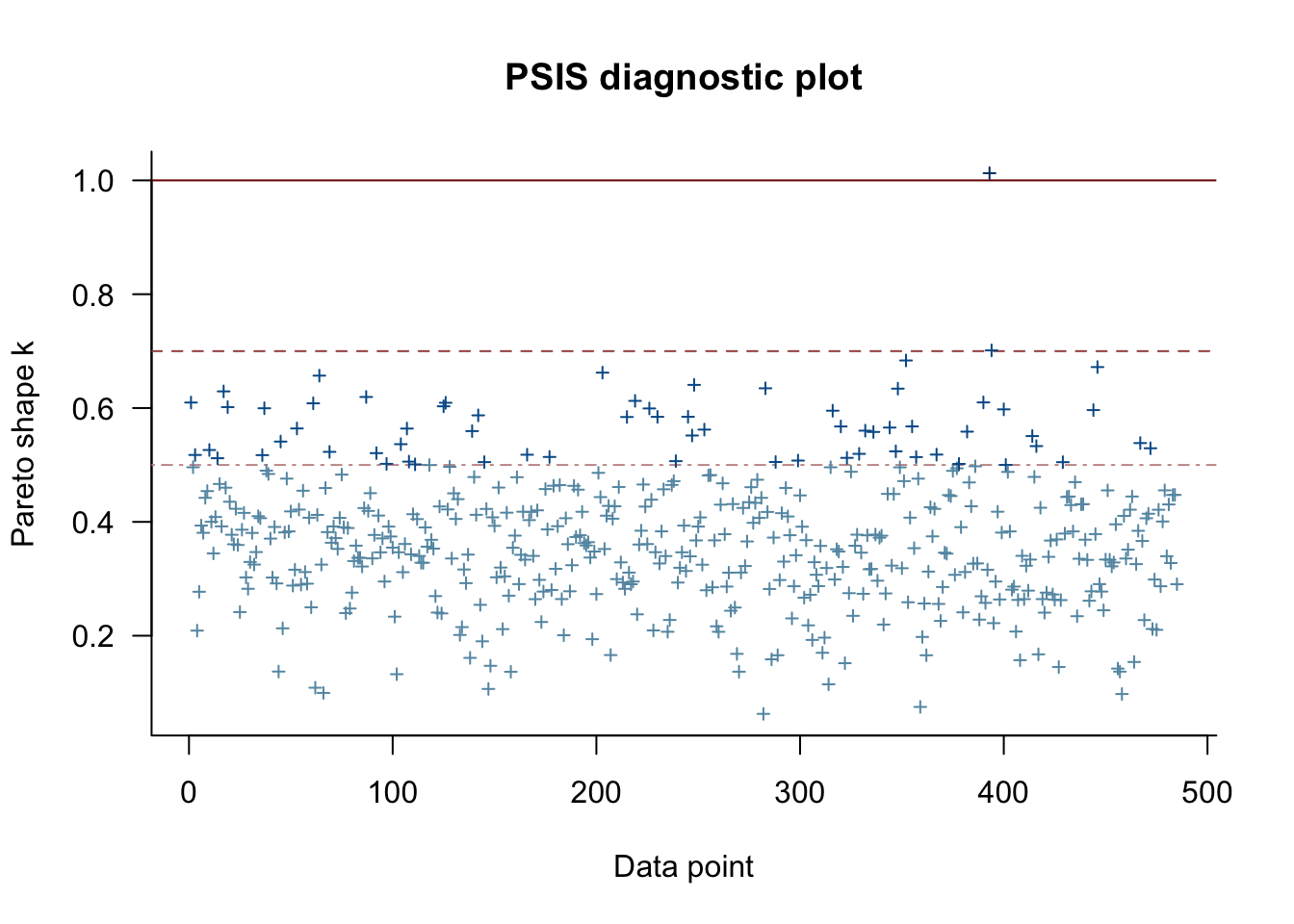
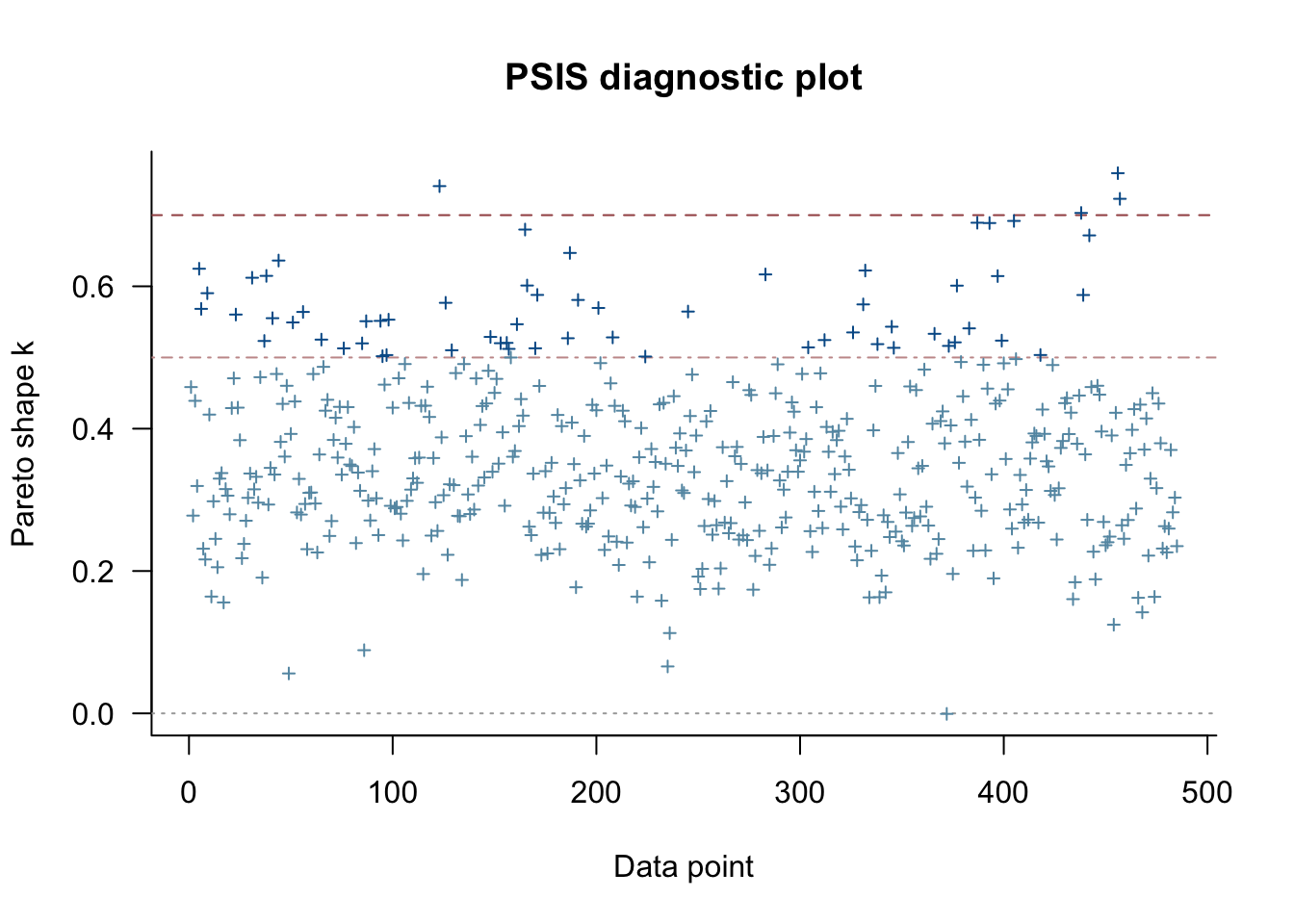
We can also look at the so-called k-hat plot, which can be useful for finding high-leverage observations in general models.
Computed from 4000 by 485 log-likelihood matrix
Estimate SE
elpd_loo -349.8 12.4
p_loo 117.8 5.2
looic 699.7 24.7
------
Monte Carlo SE of elpd_loo is NA.
Pareto k diagnostic values:
Count Pct. Min. n_eff
(-Inf, 0.5] (good) 418 86.2% 902
(0.5, 0.7] (ok) 65 13.4% 443
(0.7, 1] (bad) 1 0.2% 272
(1, Inf) (very bad) 1 0.2% 59
See help('pareto-k-diagnostic') for details.
plot(loo_posterior)
This suggests that observations 393, 394 are potentially high leverage and we should check them more carefully. I won’t be doing that today.
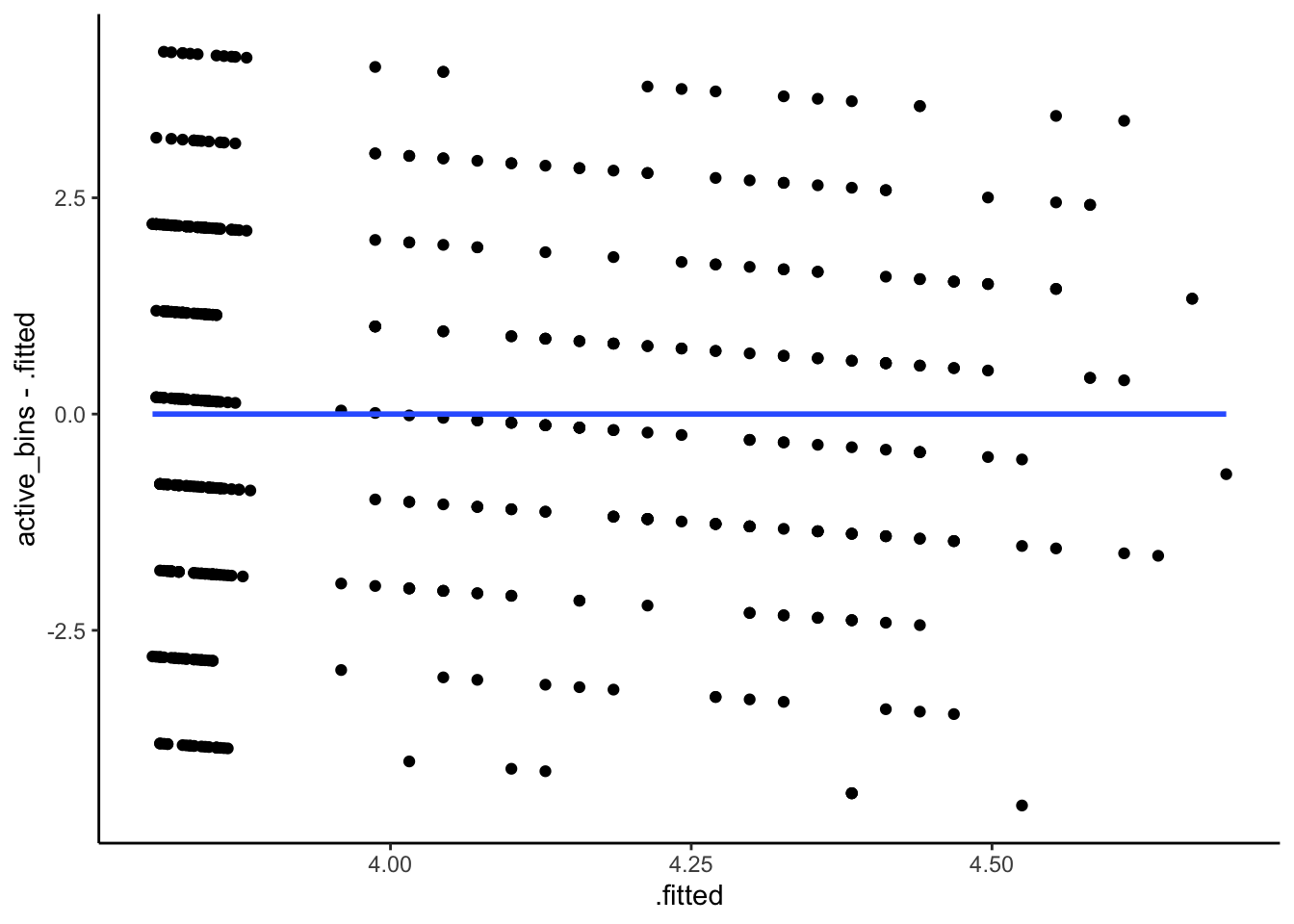
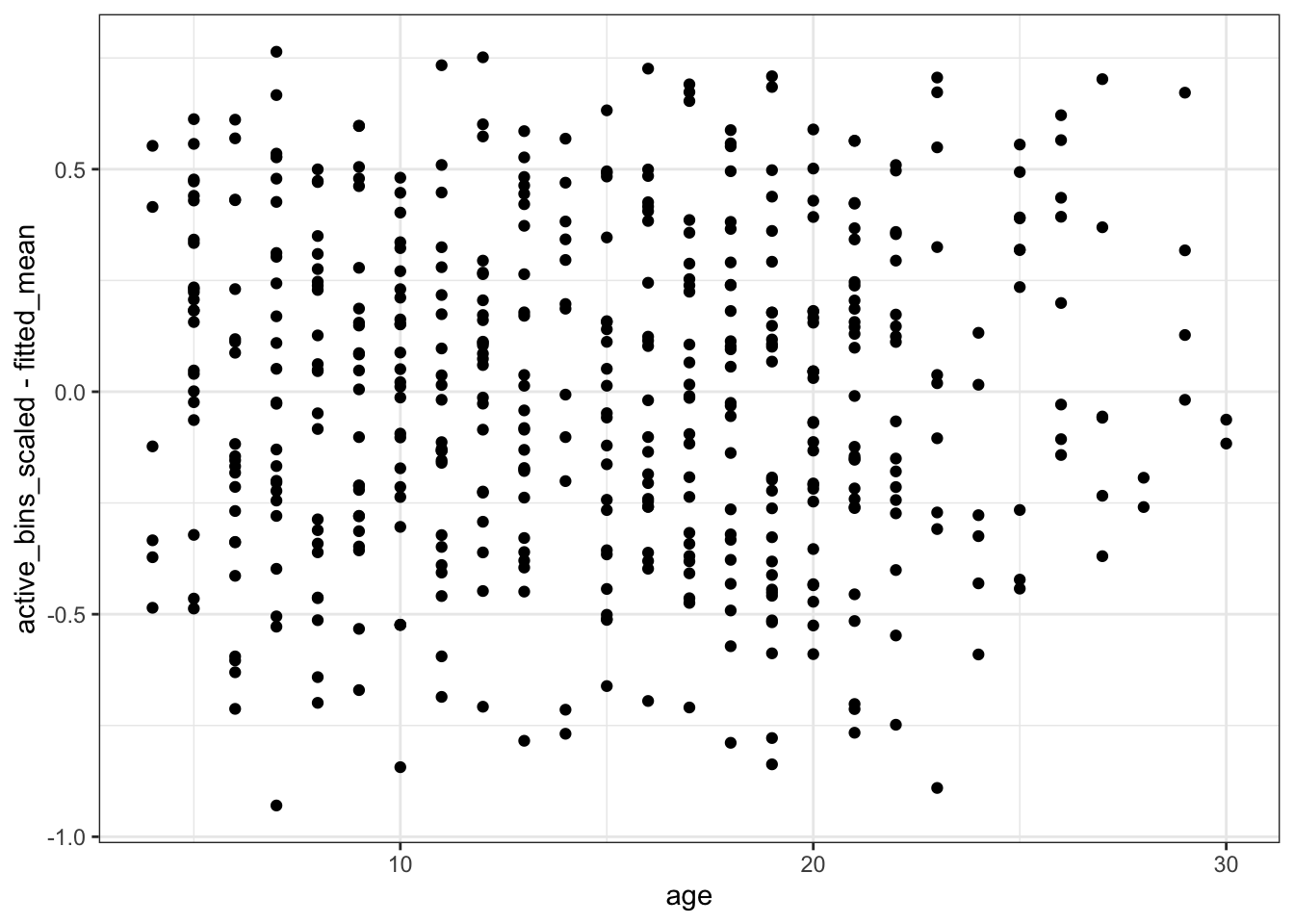
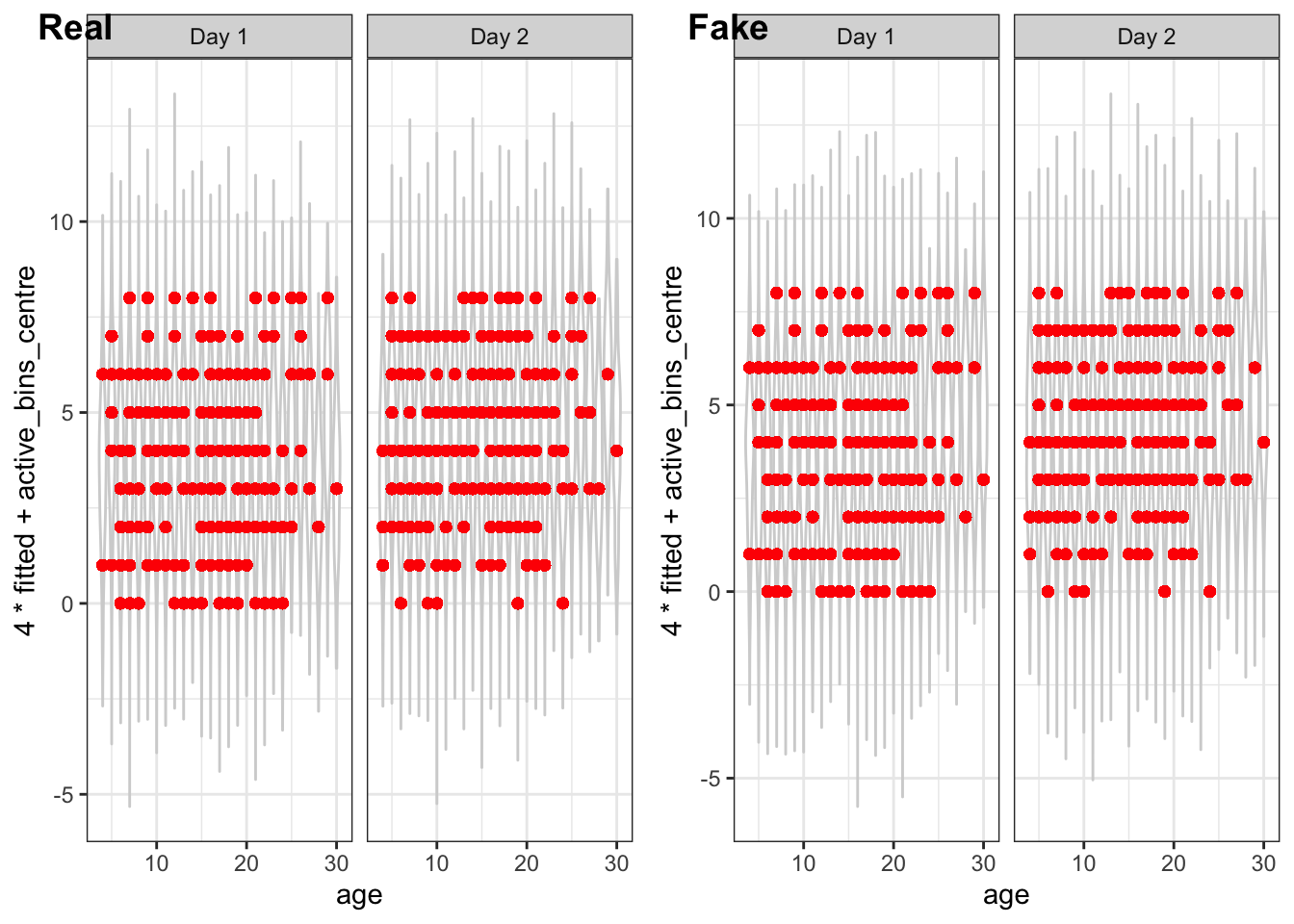
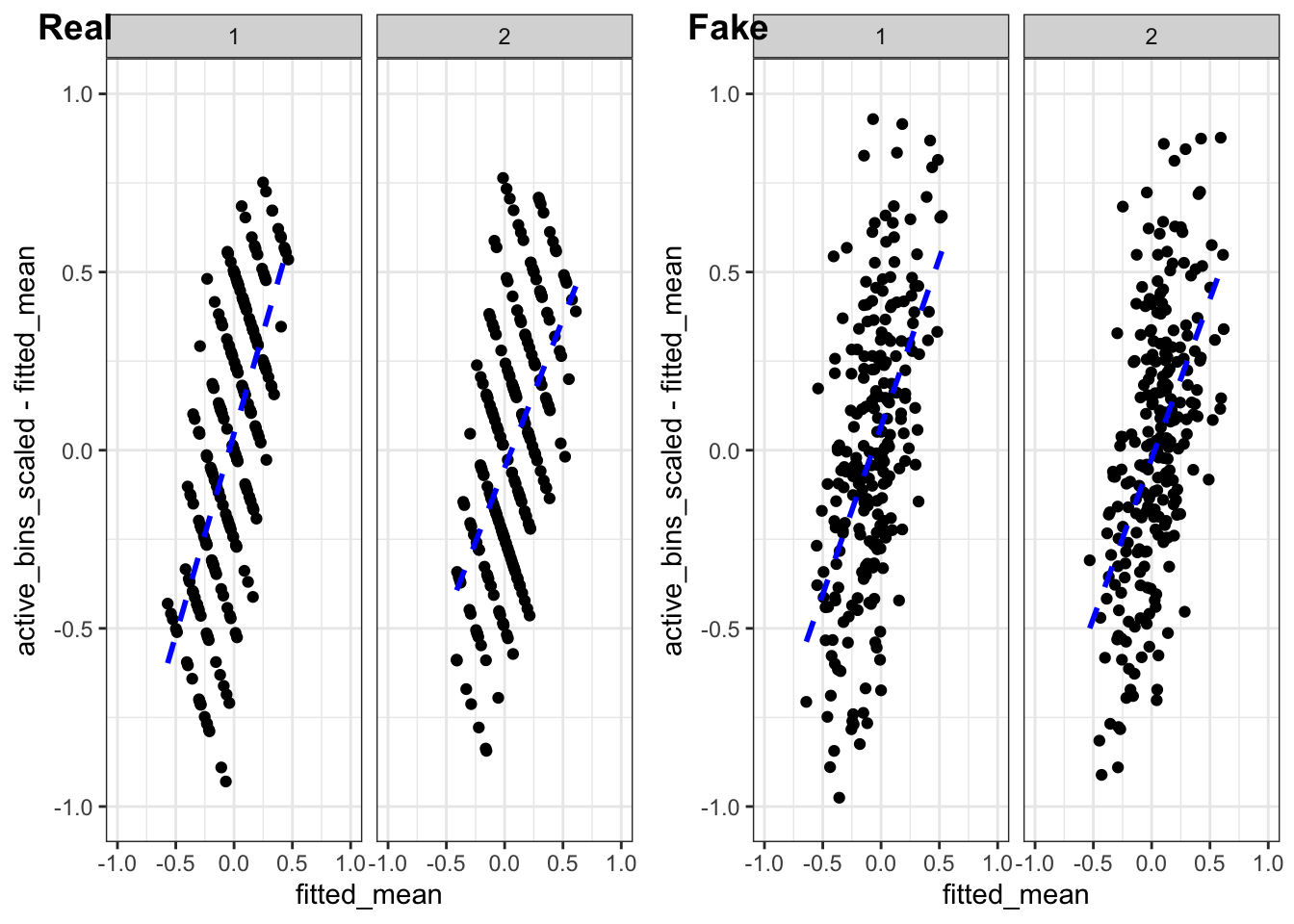
Finally, let’s look at the residuals vs the fitted values. This is a commonly used diagnostic plot in linear regression and it can be very useful for visually detecting non-linear patterns and heteroskedasticity in the residuals. So let’s make the plot32.
Hmmmm. That’s not excellent. The stripes are related to the 8 distinct values the response can take, but there is definitely a trend in the residuals. In particular, we are under-predicting small values and over-predicting large values. There is something here and we will look into it!
Understanding diagnostic plots from multilevel models
The thing is, multilevel models are notorious for having patterns that are essentially a product of the data design and not of any type of statistical misspecification. In a really great paper that you should all read, Adam Loy, Heike Hofmann, and Di Cook talk extensively about the challenges with interpreting diagnostic plots for linear mixed effects models33.
I’m not going to fully follow their recommendations, mostly because I’m too lazy34 to write a for loop, but I am going to appropriate the guts of their idea.
They note that strange patterns can occur in diagnostic plots even for correctly specified models. Moreover, we simply do not know what these patters will be. It’s too complex a function of the design, the structure, the data, and the potential misspecification. That sounds bad, but they note that we don’t need to know what pattern to expect. Why not? Because we can simulate it!
So this is the idea: Let’s simulate some fake35 data from a correctly specified model that otherwise matches with our data. We can then compare the diagnostic plots from the fake data with diagnostic plots from the real data and see if the patterns are meaningfully different.
In order to do this, we should have a method to construct multiple fake data sets. Why? Well a plot is nothing but another test statistic and we must take this variability into account.
(That said, do what I say, not what I do. This is a blog. I’m not going to code well enough to make this clean and straightforward, so I’m just going to do one.)
There is an entire theory of visual inference that uses these lineups of diagnostic plots, where one uses the real data and the rest use realisations of the null data, that is really quite interesting and well beyond the scope of this post. But if you want to know more, read the Low, Hoffman, and Cook paper!
Making new data
The first thing that we need to do is to work out how to simulate fake data from a correctly specified model with the same structure. Following the Low etc paper, I’m going to do a simple parameteric bootstrap, where I take the posterior medians of the fitted distribution and simulate data from them.
That said, there are a bunch of other options. Specifically, we have a whole bag of samples from our posterior distribution and it would be possible to use that to select values of36\((\mu, \beta, \tau, \sigma)\) for our simulation.
So let’s make some fake data and fit the model to it!
Finally, we can look at the k-hat plot. Because I’m lazy, I’m not going to put them side by side. You can scroll.
loo_fake <-LOO(posterior_draws_fake)
Warning: Found 4 observations with a pareto_k > 0.7 in model
'posterior_draws_fake'. It is recommended to set 'moment_match = TRUE' in order
to perform moment matching for problematic observations.
loo_fake
Computed from 4000 by 485 log-likelihood matrix
Estimate SE
elpd_loo -372.1 14.9
p_loo 115.4 6.1
looic 744.2 29.7
------
Monte Carlo SE of elpd_loo is NA.
Pareto k diagnostic values:
Count Pct. Min. n_eff
(-Inf, 0.5] (good) 422 87.0% 579
(0.5, 0.7] (ok) 59 12.2% 220
(0.7, 1] (bad) 4 0.8% 118
(1, Inf) (very bad) 0 0.0% <NA>
See help('pareto-k-diagnostic') for details.
plot(loo_fake)
And look: we get some extreme values. (Depending on the run we get more or less). This suggests that while it would be useful to look at the data points flagged by the k-hat statistic, it may just be sampling variation.;
All of this suggests our model assumptions are not being grossly violated. All except for that residual vs fitted values plot…
And what do you know! They look the same. (Well, minus the discretisation artefacts.)
So what the hell is going on?
Great question! It turns out that this is one of those cases where our intuition from linear models does not transfer over to multilevel models.
We can actually reason this out by thinking about a model where we have no covariates.
If we have no pooling then the observations for every monkey are, essentially, averaged to get our estimate of \(\mu_j\). If we repeat this, we will find that our \(\mu_j\) are basically37 unbiased and the corresponding residual \[
r_{ij} = y_{ij} - \mu_j
\] will have mean zero.
But that’s not what happens when we have partial pooling. When we have partial pooling we are combining our naive average38\(\bar y_j\) with the global average \(\mu\) in a way that accounts for the size of group \(j\) relative to other groups as well as the within-group variability relative to the between-group variability.
Expand for maths. Just a little
There is, in fact, a formula for it. Just in case you’re a formula sort of person. The posterior estimate for a Gaussian multilevel model with an intercept but no covariates is \[
\frac{1}{1 +\frac{\sigma^2/n}{\tau^2}}\left(\bar{y}_j + \frac{\sigma^2/n}{\tau^2} \mu\right).
\] When \(\sigma/\sqrt{n}\) is small, which happens when the sampling standard deviation of \(\bar y_j\) is small relative to the between group variation \(\tau\), this is almost equal to \(\bar{y}_j\) and there is almost no pooling. On the other hand, when \(\sigma/\sqrt{n}\) is large relative to \(\tau\), then the estimate of \(\mu_j\) will be very close to the overall mean \(\mu\).
The short version is that there is some magical number \(\alpha\), which depends on \(\tau\), \(\sigma\), and \(n_j\) such that \[
\hat \mu_j = \alpha \bar{y}_j + (1-\alpha) \mu.
\] Because of this, the residuals \[
r_{ij} = y_j - \alpha \bar{y_j} - (1-\alpha)\mu
\] are suddenly not going to have mean zero.
In fact, if we think about it a bit more, we will realise that the model will drag extreme groups to the centre, which accounts for the positive slope in the residuals vs the fitted values.
The slope in this example is quite extreme because the groups are very small (only one or two individuals). But it is a general phenomenon and it’s discussed extensively in Chapter 7 of Jim Hodges’ excellent book. His suggestion is that there isn’t really a good, general way to remove the trend. But that doesn’t mean the plot is useless. It is still able to pinpoint outliers and heteroskedasticity. You’ve just got to tilt your head.
But for the purposes of today we can notice that there don’t seem to be any extreme outliers so everything is probably ok.
Conclusion
So what have we done? Well we’ve gone through the process of fitting and scruitinising a simple Bayesian multilevel model. We’ve talked about some of the challenges associated with graphical diagnostics for structured data. And we’ve all39 learnt something about the residual-vs-fitted plot for a multilevel model.
Most importantly, we’ve all learnt the value of using fake data simulated from the posterior model to help us understand our diagnostics.
There is more to the scientific story here. It turns out that while there is no effect over 2 minutes, there is a slight effect over 20 minutes. So the conceptual replication failed, but still found some interesting things.
Of course, I’ve ignored one big elephant in the room: That data was discrete. In the end, our distributional diagnostics didn’t throw up any massive red flags, but nevertheless it could be an interesting exercise to see what happens if we use a more problem-adapted likelihood.
Last, and certainly not least, I barely scratched the surface40 of the Loy, Hoffman, and Cook paper. Anyone who is interested in fitting Gaussian multilevel models should definitely give it a read.
Footnotes
Mark insisted that I like to his google scholar rather than his website. He’s cute that way.↩︎
Mark wants me to tell you that he’s not vain he’s just moving. Sure Jan.↩︎
I know that marmosets suffer from lesbian bed death, but I’m told that a marmoset is not a macaque, which in turn is not a macaw. Ecology is fascinating.↩︎
A real problem in the world is that there aren’t enough monkeys for animal research at the best of times. Once you need aged monkeys, it’s an even smaller population. Non-human primate research is hard.↩︎
Actually 244, but one of them turned out to be blind. Animal research is a journey.↩︎
It turns out that some of the monkeys didn’t want to give up the puzzle after 20 minutes. One held out for 72 minutes before the data collection ended. Cheeky monkeys.↩︎
Did Mark make me do unspeakable, degrading, borderline immoral things to get the data? No. It’s open source. Truly the first time I’ve been disappointed that something was open source.↩︎
If statisticians abandoned linear regression we would have nothing left. We would be desiccated husks propping up the bar at 3am talking about how we used to do loads of lines in the 80s.↩︎
Our perfect amount of pool? I don’t know how metaphors work↩︎
They always take this form if there is a countable collection of exchangeable random variables. For a finite set there are a few more options. But no one talks about those.↩︎
Also known as a mixed effects or a linear mixed effects model.↩︎
There are many other ways to represnt Gaussian multilevel models. My former colleague Emi Tanaka and Francis Hui wrote a great paper on this topic.↩︎
Some particularly bold and foolish people take this to mean that priors aren’t important. They usually get their arse handed to them the moment they try to fit an even mildly complex model.↩︎
A non-exhaustive set of weird things: categorical regressors with a rare category, tail parameters, mixture models↩︎
There are situations where this is not true. For instance if you have a log or logit link function you can put reasonable bounds on your coefficients regardless of the scaling of your data. That said, the computational procedures always appreciate a bit of scaling. If there’s one thing that computers hate more that big numbers it’s small numbers.↩︎
Of course, we know that the there are only 8 fifteen second intervals in two minutes, so we could use this information to make a data-independent scaling. To be brutally francis with you, that’s what you should probably do in this situation, but I’m trying to be pedagogical so let’s at least think about scaling it by the standard deviation.↩︎
Fixed scaling is always easier than data-dependent scaling↩︎
A real trick for young players is scaling new data by the mean and standard deviation of the new data rather than the old data. That’s a very subtle bug that can be very hard to squash.↩︎
The tidymodels package in R is a great example of an ecosystem that does this properly. Max and Julia’s book on using tidymodels is very excellent and well worth a read.↩︎
Of all of the things in this post, this has been the most aggressively fact checked one↩︎
In prior width and on grindr, you should always expect that he’s rounding up.↩︎
In some places, we would call this a random effect.↩︎
He is very lovely. Many people would prefer that I was him.↩︎
It’s possible the the prior on \(\tau\) might be too wide. If we were doing a logistic regression, these priors would definitely be too wide. And if we had a lot of different random terms (eg if we had lots of different species or lots of different labs) then they would also probably be too wide. But they are better than not having priors.↩︎
Not the most computationally efficient, but the easiest. Also because it’s the same code we will later use to fit the model, we are evaluating the priors that are actually used and not the ones that we think we’re using.↩︎
It’s number 88, but because our prior is exchangeable it does not matter which monkey we do this for!↩︎
I also checked different values of age as well as looking at the posterior mean (via posterior_epred) and the conclusions stay the same.↩︎
The numbers will never be exactly equal, but they are of similar orders of magnitude.↩︎
Or if you get some sort of error or warning from lme4↩︎
So there’s a wrinkle here. Technically, all of the residuals have different variances, which is annoying. You typically studentise them using the leverage scores, but this is a touch trickier for multilevel models. Chapter 7 of Jim Hodges’s excellent book contains a really good discussion.↩︎
Once again, we are not studentizing the residuals. I’m sorry.↩︎
Another name for a multilevel model with a Gaussian response↩︎
Also because all of my data plots are gonna be stripey as hell, and that kinda destroys the point of visual inference.↩︎
Note that I am not using values of \(\mu_j\)! I will simulate those from the normal distribution to ensure correct model specification. For the same reason, I am not using a residual bootstrap. The aim here is not to assess uncertainty so much as it is to ↩︎
This is a bit more complex when you’re Bayesian, but the intuition still holds. The difference is that now it is asymptotic↩︎
This is the average of all observations in group j. \[
\bar y_j = \frac{1}{n_j} \sum_{i=1}^{n_j} y_{ij}.
\]↩︎
I mean, some of us knew this. Personally, I only remembered after I saw it and swore a bit.↩︎
In particular, they have an interesting discussion on assessing the distributional assumption for \(\mu_j\).↩︎
@online{simpson2022,
author = {Simpson, Dan},
title = {A First Look at Multilevel Regression; or {Everybody’s} Got
Something to Hide Except Me and My Macaques},
date = {2022-09-06},
url = {https://dansblog.netlify.app/2022-09-04-everybodys-got-something-to-hide-except-me-and-my-monkey.html},
langid = {en}
}